«Noindex» wird ab September nicht mehr unterstützt
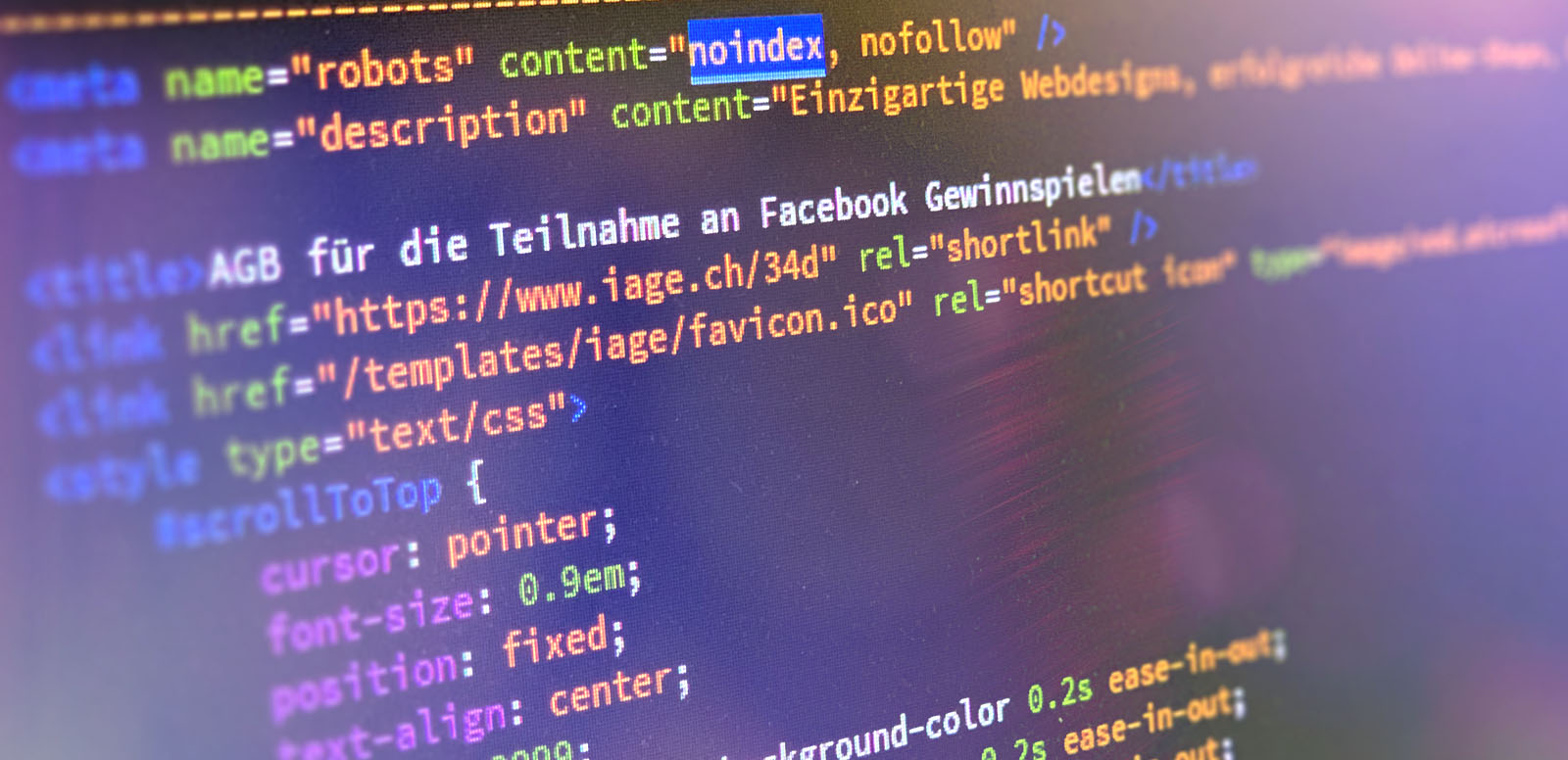
Google beachtet das «Noindex» in der robots.txt ab dem 01.09.2019 nicht mehr. Erfahren Sie jetzt mehr dazu.
Google kündigt im Webmaster Central Blog an, das Robots-Exklusion-Standard-Protokoll zu einem richtigen Internet-Standard zu machen. Folgende Anweisungen werden vom Google-Bot dann nicht mehr beachtet: «Noindex», «Nofollow», «Crawl-delay».
Wichtig: Alle unsere Kunden-Webseiten sind von dieser aktuellen Google Änderung nicht betroffen.
Hintergrund: was ist robots.txt und wofür ist es zuständig?
Die robots.txt, genauer gesagt das Robots-Exklusion-Standard-Protokoll (REP), ist eine Textdatei, die seit über zwei Jahrzehnten der inoffizielle Standard, der Suchmaschinen-Crawlern vorgibt, welche Teile einer Webseite durchsucht und welche ignoriert werden. Sie haben einen grossen Einfluss auf die Indexierung, die Suchmaschinenoptimierung und die Analyse der Webseite.
Sollte Ihre Webseite von den Änderungen betroffen sein, bietet Google folgende fünf Alternativen:
- Die Noindex-Anweisung in den X-Robots-Tag im HTTP-Header oder die Meta Robots-Tags setzen. Hier gelten sie weiterhin.
- HTTP-Statuscodes 404 und 410: Beide Statuscodes bedeuten, dass die Seite nicht vorhanden ist. Diese URLs werden nach dem Crawlen und Verarbeiten aus dem Google-Index entfernt.
- Passwortschutz nutzen: Inhalte hinter einen Login zu setzen, schützt sie davor, vom Google-Index erfasst zu werden.
- Disallow in der Robots.txt einsetzen: Suchmaschinen können nur Seiten indexieren, von denen sie wissen.
- In der Google Search Console das Tool Remove URL verwenden: Eine einfache und schnelle Methode, um eine URL temporär aus den Google Suchergebnissen zu entfernen.
Fazit: Die meisten Webseiten werden von den aktuellen Google-Änderungen bei den robots.txt-Dateien nicht betroffen sein. Eine regelmässige Kontrolle der Inhalte der eigenen Datei lohnt sich aber dennoch.